Industry-specific language models, multi-speaker identification, and professional output formats designed for high-fidelity recordings

Speech engine optimized for uncompressed audio captures nuances and details lost in compressed formats
Files processed on EU-based servers with encryption at rest and in transit, GDPR-compliant infrastructure

Specialized models for medical terminology, legal proceedings, financial discussions and academic discourse
Download finished transcripts as Word documents, PDFs, spreadsheets, plain text, or timed subtitle files
Automated pipeline turns Apple Lossless files into editable text
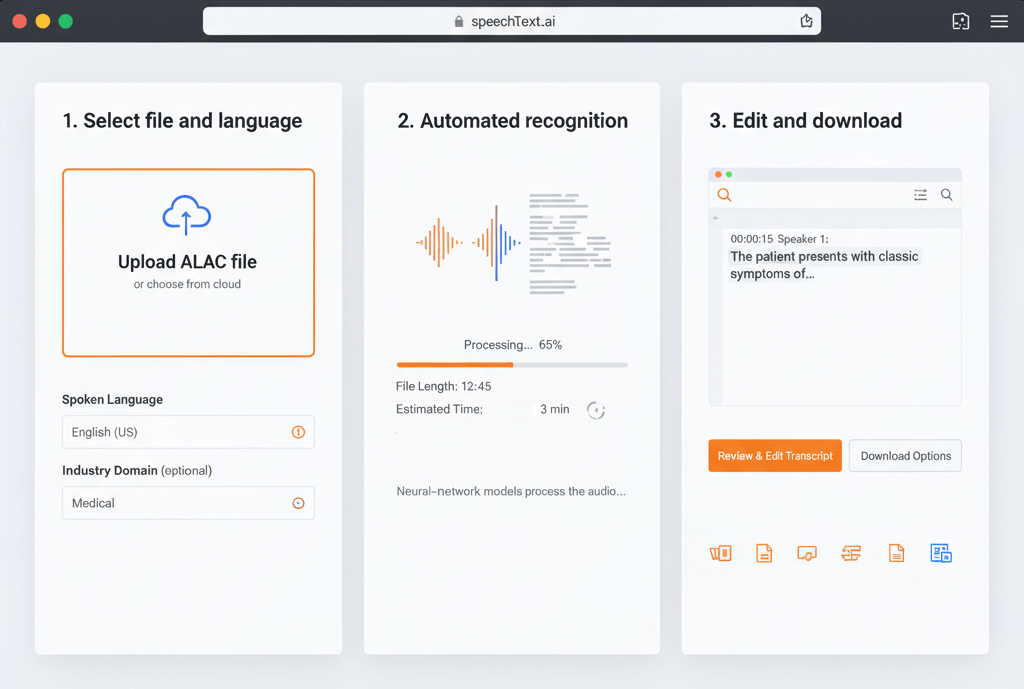
Upload the ALAC file from local storage or cloud drive. Pick the spoken language and optionally specify an industry domain to improve recognition of specialized terms.
Neural-network models process the audio in the cloud, identifying phonemes, words and punctuation. Processing time scales with file length; most recordings finish in minutes.
Review the transcript in the built-in editor, correct any errors, and export as plain text, formatted document, spreadsheet or subtitle track. Every output includes optional timestamps and speaker labels.
Apple Lossless Audio Codec delivers bit-perfect audio preservation, making it a preferred format for critical listening
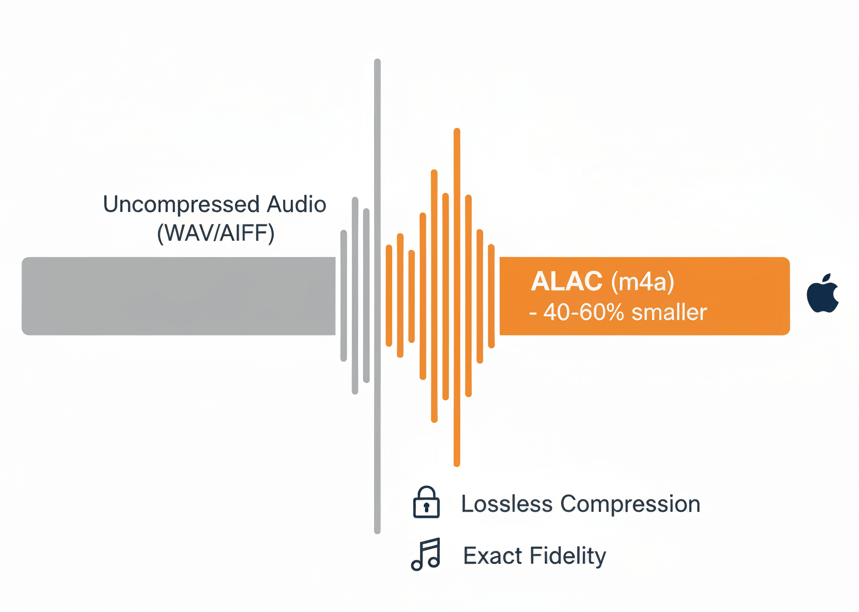
ALAC compresses audio without discarding any information, unlike lossy codecs. Files typically use the .m4a extension. Developed by Apple and later open-sourced, the codec maintains exact waveform fidelity while reducing storage by approximately 40–60% compared to uncompressed WAV or AIFF.
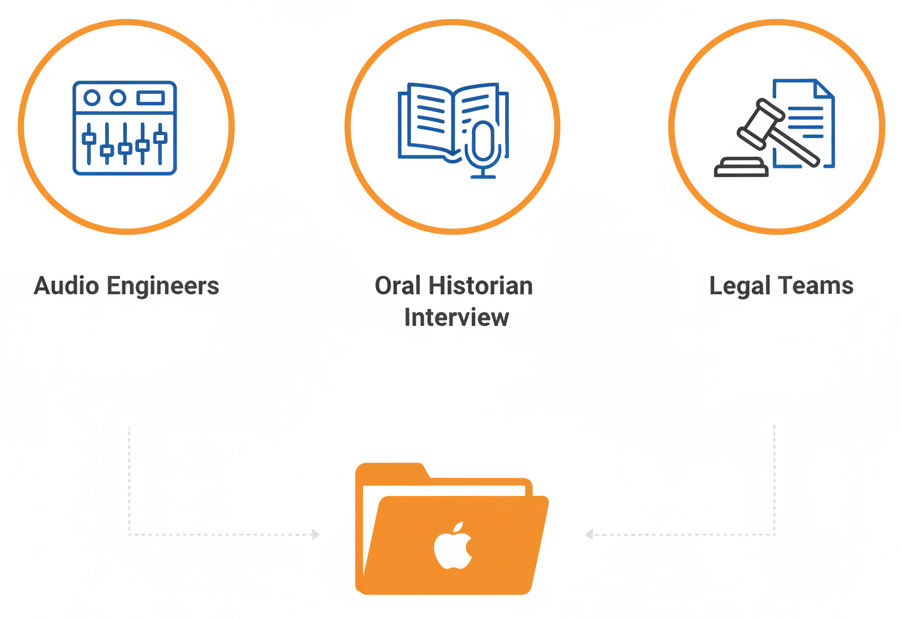
Professional audio engineers, musicians and archivists choose ALAC when pristine quality is non-negotiable but storage efficiency still matters. Recording studios export session mixes, oral historians preserve interviews, and legal teams archive depositions in ALAC to ensure no acoustic detail is lost during long-term storage.
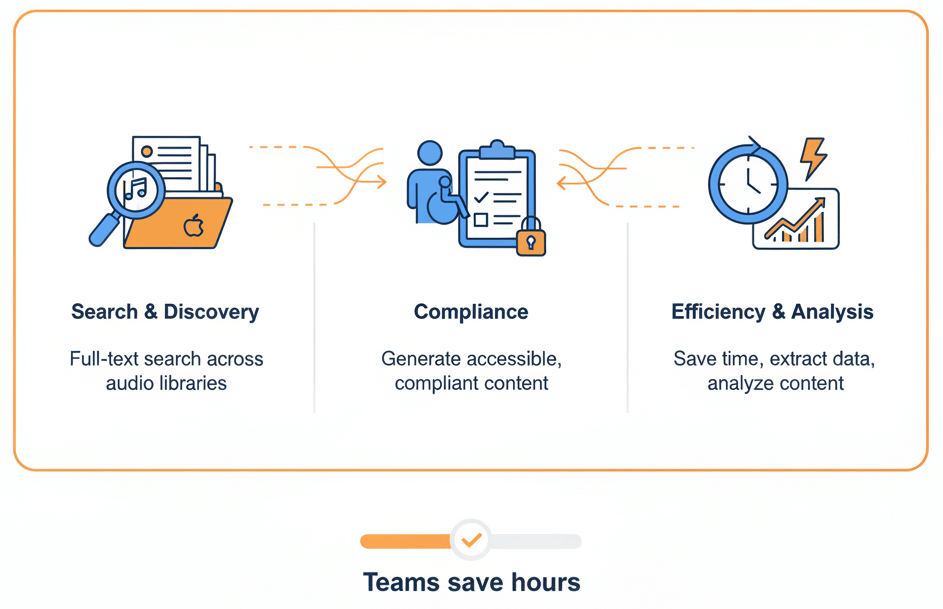
Converting ALAC to text unlocks the content for full-text search, compliance review, citation and redistribution. Transcripts enable keyword indexing across large audio libraries, facilitate accessibility compliance, and allow rapid extraction of quotes or data points without repeated manual playback. Teams save hours by reading instead of listening.
Organizations across industries rely on accurate ALAC to text conversion for documentation, compliance and content workflows
Upload the ALAC file, select a language, and start the transcription. The system decodes the lossless audio stream, feeds it into speech recognition models, and returns a text document. Edit the result in the browser and download in the preferred format.
Yes. After transcription completes, export the text directly to a formatted PDF document. Other supported formats include Microsoft Word (DOCX), plain text (TXT), Excel (XLSX), and subtitle files (SRT, VTT) for video workflows.
Lossless audio preserves every acoustic detail, which can help recognition models distinguish speech from background sounds and capture subtle phonetic cues. For recordings with challenging acoustics or overlapping speakers, the additional fidelity often results in fewer errors.
File limits depend on the subscription tier. Free trials typically allow files up to a specified duration or size. Paid plans support longer recordings and batch processing. Check the pricing page for specific quotas.
All uploads and transcripts are encrypted in transit and at rest on servers located in the European Union. Data handling complies with GDPR requirements, and files can be deleted from the account dashboard at any time.
While ALAC preserves full audio fidelity, transcription accuracy still depends on source recording conditions. Use close microphone placement, minimize ambient noise and reverberation, maintain consistent volume levels, and record at standard sample rates (44.1 or 48 kHz). Lossless compression ensures the speech engine receives maximum information content for recognition.
While ALAC preserves full audio fidelity, transcription accuracy still depends on source recording conditions. Use close microphone placement, minimize ambient noise and reverberation, maintain consistent volume levels, and record at standard sample rates (44.1 or 48 kHz). Lossless compression ensures the speech engine receives maximum information content for recognition.