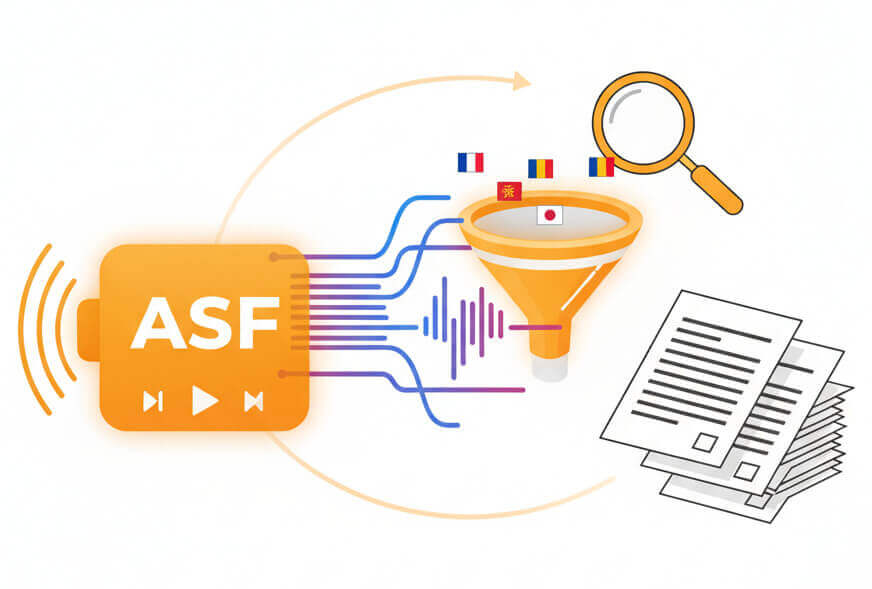
Specialized engine built to handle streaming formats and low-bitrate Windows Media audio

Process ASF media in over 50 languages with native speaker-trained acoustic models

Files processed on European infrastructure with encrypted storage and automatic deletion options
Automatic diarization separates multiple voices in conference calls and panel recordings
Download transcripts as editable documents, subtitles, or structured data for analysis
Automated speech-to-text pipeline handles format conversion and linguistic analysis
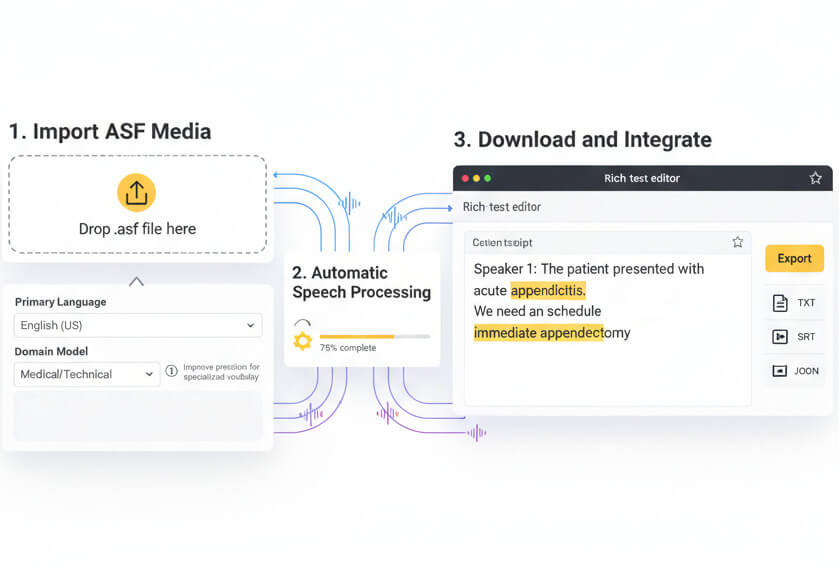
Drop an .asf file into the platform. Select the primary language spoken in the recording. For specialized vocabulary-medical terms, technical jargon, or industry-specific phrases choose a matching domain model to improve recognition precision.
The platform extracts audio streams from the ASF container and runs deep-learning models trained on diverse speech patterns. Processing happens in the background without manual intervention. Large files are segmented and processed in parallel for faster turnaround.
Review the machine-generated transcript in the browser editor. Correct any misrecognized words or add custom formatting. Export the final document as TXT for archival, DOCX for collaborative editing, SRT for video captioning, or JSON for custom integrations.
Advanced Systems Format is a Microsoft container designed for network streaming and progressive download
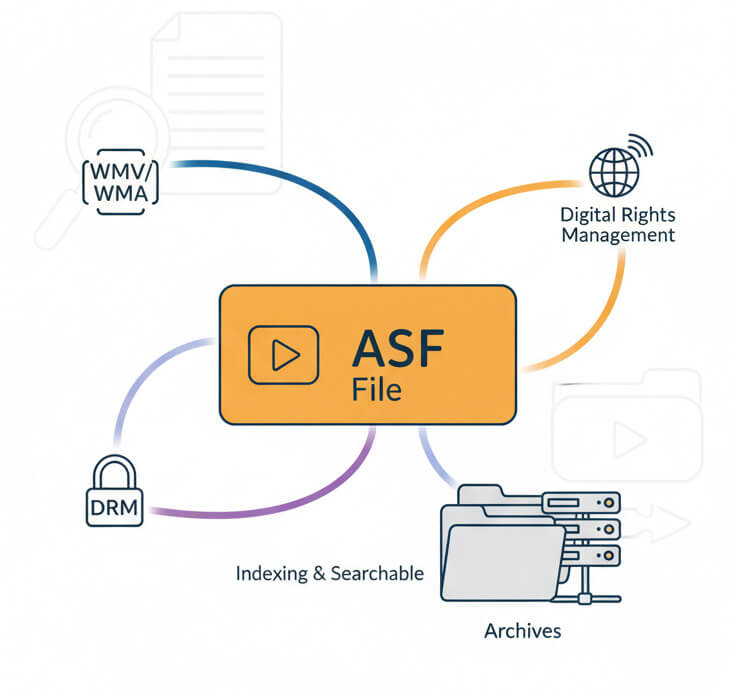
ASF files wrap Windows Media codecs in a flexible container structure. Originally developed for streaming media over the early internet, ASF supports metadata, multiple bitrates, and digital rights management. Many corporate and broadcast archives still hold thousands of ASF recordings from the 2000s that need to be indexed and made searchable.
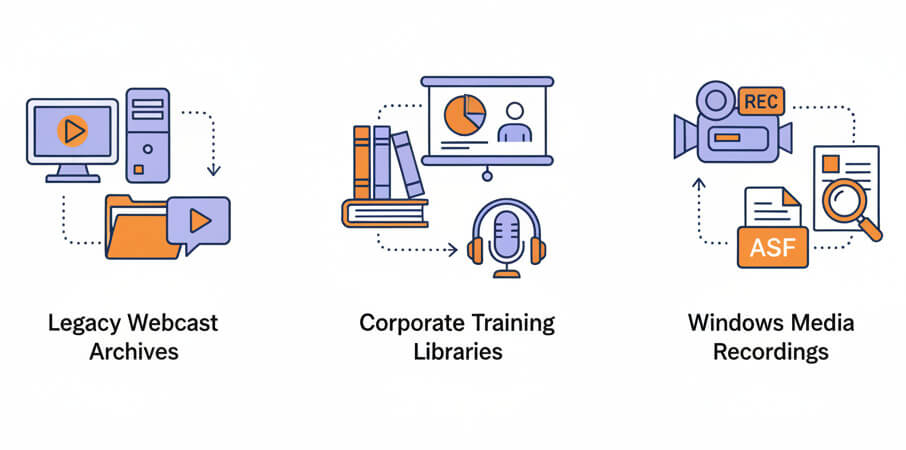
ASF is found in legacy webcast archives, older corporate training libraries, and media recorded with Windows Media Encoder. While newer formats have largely replaced ASF for production, organizations migrating or digitizing old content encounter ASF regularly. Converting these files to text opens up keyword search, closed captioning, and compliance review for material that would otherwise remain locked in binary containers.
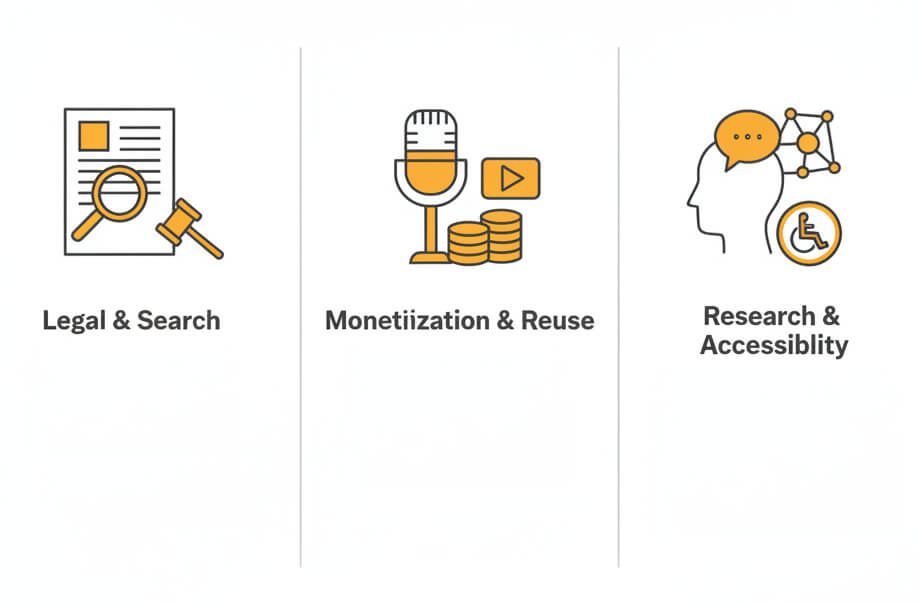
Transcribing archived ASF recordings unlocks important institutional knowledge. Legal teams can search deposition archives for specific testimony. Broadcasters can monetize old interviews by republishing transcripts. Researchers can analyze historical focus groups without manually listening to hundreds of hours of tape. Text transcripts also improve accessibility for deaf and hard-of-hearing audiences and enable machine translation into other languages.
Organizations across sectors rely on ASF transcription to modernize legacy audio libraries and streamline knowledge retrieval

Yes. The entire process runs in the browser. Upload an ASF file, select language and domain preferences, and download the completed transcript. No desktop application or codec pack is needed.
The platform accepts files up to several gigabytes and processes them in parallel segments. For bulk migration projects, e.g. hundreds or thousands of ASF recordings, API access and batch workflow tools are available to automate upload, transcription, and export at scale.
Our speech models are trained on noisy, low-bitrate samples and often recover intelligible text from challenging recordings. Results vary by codec settings and background conditions. A free trial lets anyone test accuracy on their own material before committing to a paid plan.
Every word is aligned to its position in the source media. Timestamps appear in exports and can be toggled in document formats. This alignment simplifies fact-checking, clipping highlights, and syncing transcripts with video editors.
All processing occurs on European servers under GDPR jurisdiction. Files and transcripts are encrypted in transit and at rest. Automatic deletion policies remove source media and transcripts after a set retention window.