
Professional speech extraction from tracker modules with automated processing and flexible output

Speech recognition engine supports over 30 languages for global S3M sample libraries

Files remain private during conversion with encrypted transfer and EU-based infrastructure

Process multiple S3M files simultaneously to convert entire archives efficiently

Save results as TXT, PDF, DOCX, or subtitle formats for downstream use
Simple three-step workflow for extracting speech from module files

Drag and drop the .s3m module file into the upload zone. The system automatically detects embedded audio samples and prepares them for speech analysis. Set the primary language to improve recognition accuracy.
The AI engine isolates voice channels within the module structure and applies speech-to-text algorithms. Processing time scales with sample count and length, typically completing within minutes for standard files.
Review recognized text in the built-in editor, adjust formatting or punctuation, then export. Choose between plain text for archiving, PDF for sharing, or SRT if synchronizing captions back to rendered audio.
S3M is a legacy tracker module format storing pattern data and digital audio samples in a single container
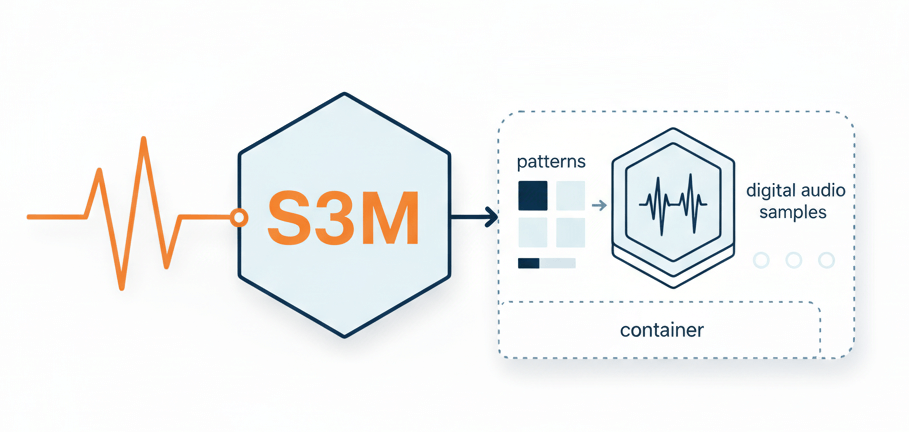
The S3M format originated with Scream Tracker 3 in the early 1990s. Each .s3m file combines note sequences with raw PCM samples. Some modules include vocal recordings, spoken tags, or voice effects embedded as sample instruments, making them candidates for speech extraction and text conversion.
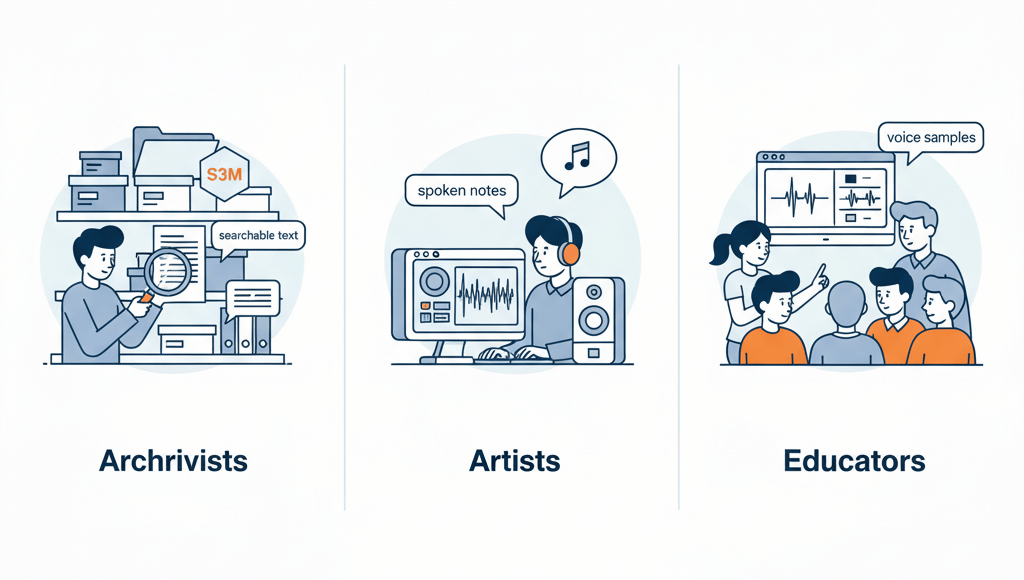
Archivists encounter S3M files containing demo-scene speech intros, artists discovering old tracker projects with spoken notes, or educators analyzing retro computer music with voice samples. Converting embedded speech to searchable text simplifies cataloging, preserves historical metadata, and enables keyword-based retrieval from large module collections.
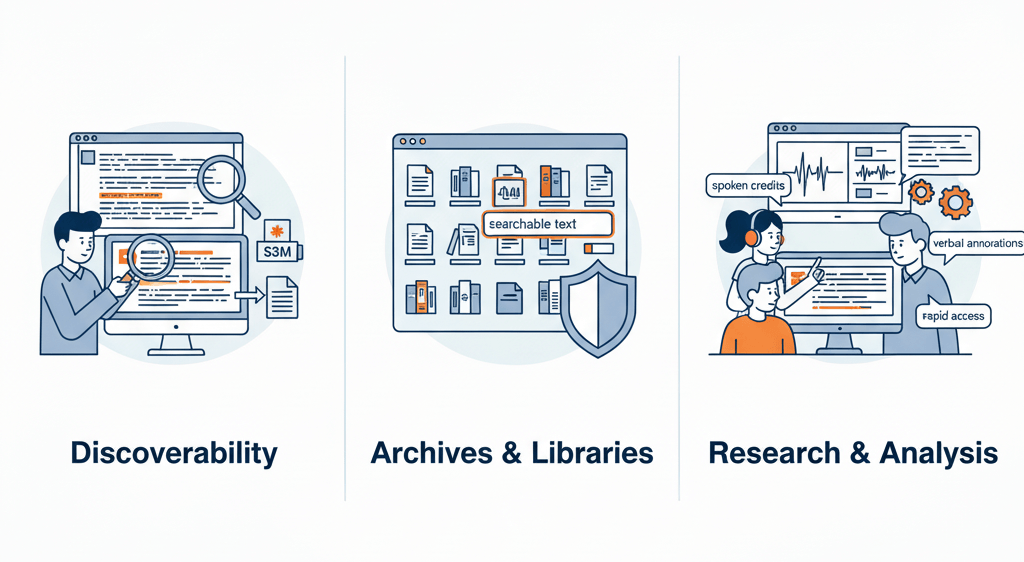
Text transcripts unlock hidden information inside tracker modules. Spoken credits, tutorial commentary, or artistic statements become discoverable and indexable. Museums and digital libraries benefit from full-text search across audio artifacts. Researchers studying computer music history gain rapid access to verbal annotations without manual playback of hundreds of files.
Organizations and individuals converting S3M audio samples into structured, searchable documentation

Upload the .s3m file, wait for the platform to extract and analyze audio samples, then download the resulting transcript in the preferred format. The engine isolates speech channels automatically and applies recognition models without manual intervention.
A trial account allows testing the full S3M transcription pipeline at no charge. Process sample files to evaluate accuracy and explore export options before committing to a subscription.
After transcription completes, select PDF from the export menu to generate a formatted document. Alternative outputs include DOCX for editing, TXT for plain archives, and SRT or VTT for subtitle workflows.
Modules with high sample rates, minimal background music during speech, and clear vocal recordings produce higher accuracy. Files mixing voice heavily with instrument tracks may require manual review to separate recognized words from noise artifacts.
All S3M uploads and extracted audio remain on servers located exclusively in the European Union, subject to strict GDPR regulations. Encryption protects data in transit and at rest. Files never transfer outside EU jurisdiction, ensuring compliance for sensitive or archival material.