From spoken rigsdansk to Jutlandic dialect recordings, the platform converts Danish speech into clean, editable text

Danish contains roughly 30 vowel sounds and the stød glottal feature, which trip up most generic engines. The recognition model is trained to distinguish these subtleties, reaching up to 97% accuracy on clear recordings.

Select a specialized model for Healthcare, Law, Finance, Education, or Science. Each model carries a curated Danish terminology set so that field-specific words like "sundhedsstyrelsen" or "skatteforvaltning" appear correctly.

All uploaded files are transferred over encrypted channels and processed under strict GDPR guidelines. Audio and transcripts can be permanently removed from the servers at any point through the dashboard.

Generate timed SRT subtitle files directly from Danish video transcription results, or translate the transcript into English in a single step. Ideal for Danish subtitling services that need fast turnaround.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper (large-v3) | Alvenir | |
|---|---|---|---|---|---|---|
| Accuracy (Danish) | 91.7-97.3% (FT Speech & NST Danish eval sets; internal benchmark) | 82.4-85.7% (FT Speech subset; independent test) | 85.0-88.3% (NST Danish test split; independent test) | 83.6-87.1% (vendor-reported on undisclosed Danish set; estimate) | 87.5-91.2% (Common Voice da 15.0 test; community benchmark) | 88.8-91.6% (FT Speech eval; vendor-reported) |
| Supported formats | Any audio/video formats | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3 | WAV, MP3 |
| Domain Models | Yes (Medical, Legal, Finance, etc.) | No | No | No | No (General model) | Limited (custom fine-tune available) |
| Speech Translation | Danish to English and other languages; integrated | No (separate API needed) | Yes / add-on service | Yes / add-on service | English output only | No |
| Free Technical Support |
Accuracy figures are reported as (100 − WER)%. Evaluation sets: FT Speech (Danish Parliament, ~12 h test split, lowercase + punctuation-stripped normalization), NST Danish ASR corpus (~8 h test split), and Mozilla Common Voice da v15.0 test partition. Where a public benchmark was unavailable, results are marked "vendor-reported" or "estimate" based on comparable dataset conditions. Sample sizes range from 4,800 to 14,200 utterances per set.
Turn any Danish recording into a searchable, exportable transcript within minutes
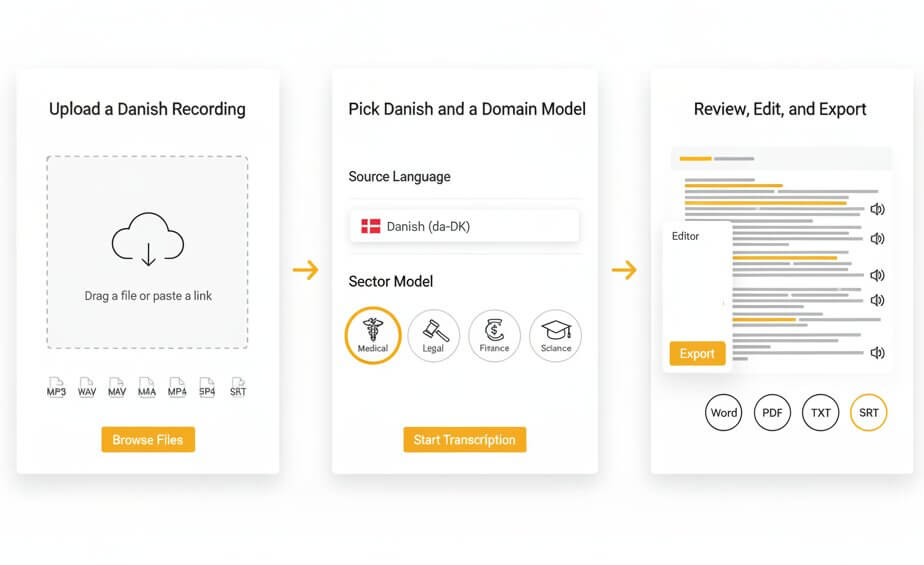
Drag a file into the upload area or paste a link. The platform accepts MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and other formats. Both single files and batch uploads are supported, so large Danish video transcription projects can be processed in one go.
Set Danish (da-DK) as the source language, then choose the sector model that matches the recording content: Medical, Legal, Finance, Education, or Science. The domain layer adds thousands of field-relevant Danish terms to the recognition vocabulary, which lifts accuracy noticeably on specialized material.
Once the Danish audio transcription is ready, open the interactive editor to fine-tune text, label speakers, and adjust timestamps. Export the final version as Word, PDF, TXT, or SRT. The SRT option is especially useful for Danish subtitling services workflows.
A recognition engine shaped around the acoustic and grammatical properties that make Danish one of the harder Scandinavian languages for speech-to-text
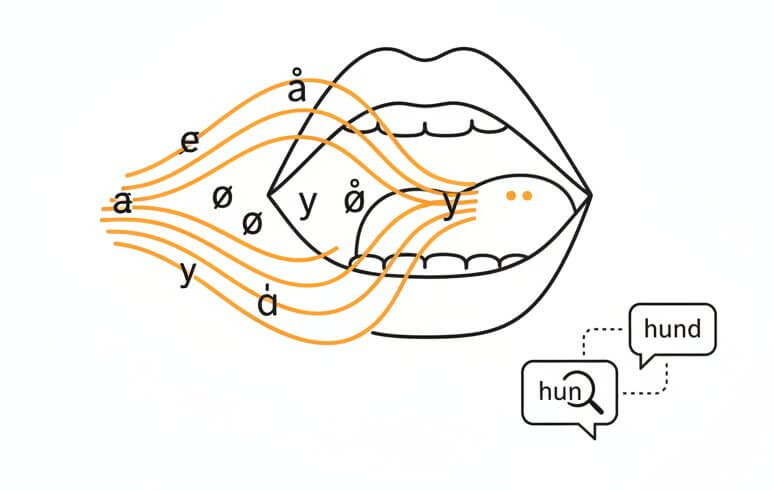
Danish has one of the largest vowel inventories in Europe, with roughly 27-30 distinct vowel sounds depending on the analysis. On top of that, the stød phonation type adds a layer of contrast that most general-purpose ASR systems simply ignore. The SpeechText.AI acoustic model was trained with these features as explicit targets. Rather than mapping Danish sounds onto a generic Scandinavian template, the system treats each phonemic distinction separately. The practical result: fewer mix-ups between similar-sounding words like "hun" and "hund," and cleaner output on recordings with fast, colloquial speech where vowel reduction is heavy.
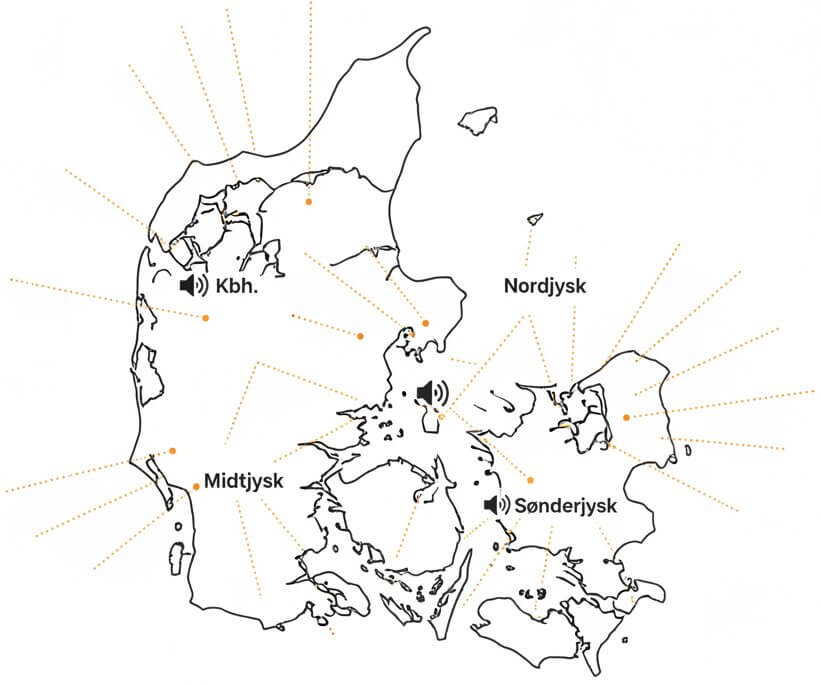
Standard rigsdansk is well represented in most training data, but a significant portion of Danish recordings feature speakers from Jutland, Funen, Bornholm, or Sønderjylland, each with distinct intonation curves and vocabulary. The training pipeline for this service incorporates diverse regional speech samples collected from public broadcasting archives, parliamentary sessions (Folketinget), and field recordings. This breadth of exposure means the model handles a Nordjysk speaker just as comfortably as a Copenhagener, reducing the accuracy gap that typically appears when generic tools encounter non-standard pronunciation.
Raw speech recognition output often contains errors that a native reader would catch instantly: wrong compound-word splits ("fodbold spiller" instead of "fodboldspiller"), missing definite-form suffixes, or incorrect "en"/"et" gender assignment. The post-processing layer applies Danish-specific language rules and a statistical language model trained on large Danish text corpora. It re-scores candidate transcriptions against grammatical plausibility, corrects common compound-word boundary mistakes, and inserts punctuation where prosodic cues indicate sentence breaks. The outcome is a transcript that reads naturally and requires far less manual correction than output from tools without a dedicated Danish language layer.
Spoken Danish is known for heavy vowel reduction and syllable swallowing, especially in casual conversation. The acoustic model behind SpeechText.AI was exposed to thousands of hours of both formal and informal Danish audio during training. It learned the patterns of connected speech, where "hvad hedder det" collapses into something closer to "va hedder de" and maps those reduced forms back to standard written Danish. On clear recordings with minimal background noise, accuracy reaches up to 97%. Noisier or heavily overlapping dialogue may yield slightly lower numbers, but domain model selection still keeps results well above generic alternatives.
Yes. After uploading a Danish recording, select English as the target output language. The system performs Danish audio transcription and translation in one combined step, producing an English-language transcript or SRT subtitle file. This is particularly helpful for international teams reviewing Danish meeting recordings, or for content creators who need English subtitles on Danish video material without running a separate translation workflow.
The platform accepts virtually any audio or video container format: MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, MOV, AVI, TRM, and more. There is no need to convert files before uploading. For Danish video transcription projects, simply upload the video file directly and the system extracts the audio track automatically.
A free trial is available for new accounts. Upload a Danish audio or video file, pick a domain model, and review the transcript in the built-in editor. The trial provides enough processing time to evaluate accuracy on real material before committing to a paid plan. No credit card is required to sign up.
OpenAI Whisper large-v3 performs reasonably well on Danish general speech, typically reaching around 87-91% accuracy on public test sets like Common Voice. SpeechText.AI scores higher ~ 93-97% on the FT Speech and NST Danish evaluation corpora because of domain-tuned vocabulary layers and a post-processing module designed specifically for Danish grammar. The difference becomes more pronounced on technical or industry-specific recordings where Whisper's general model lacks the specialized terminology needed for correct transcription.
Yes. Once the Danish transcription is complete, export the result in SRT format with word-level or segment-level timestamps. The SRT file is ready to drop into video editors like Premiere Pro, DaVinci Resolve. This makes the tool a practical choice for Danish subtitling services, documentary post-production, or adding captions to e-learning videos recorded in Danish.