From transcribing Deutsch recordings to translating German speech into English, every step is handled automatically

German is famous for long compound nouns like Rechtsschutzversicherungsgesellschaft. The transcription engine parses these formations correctly instead of splitting them into unrelated fragments.

Speakers from Bavaria, Austria, and Switzerland sound different from standard Hochdeutsch. Domain models are trained on regional speech patterns so accuracy stays high regardless of accent.

All uploads are encrypted in transit and at rest. The platform complies with both the EU General Data Protection Regulation and the German Datenschutz-Grundverordnung. Files can be deleted permanently at any time.

Need an English version? Upload a Deutsch recording and receive a translated transcript or SRT subtitle file in one automated step, no manual work required.
| SpeechText.AI | OpenAI Whisper | Google Cloud | Amazon Transcribe | Microsoft Azure | |
|---|---|---|---|---|---|
| Accuracy (German) | 93.8-96.2% (Tuda-DE v2 / MLS-de test, internal evaluation) | 89.5-93.1% (MLS-de test, open community benchmark) | 87.2-90.4% (Tuda-DE v2, independent evaluation) | 88.1-91.3% (MLS-de test, independent evaluation) | 88.6-91.8% (vendor report, Custom Speech docs) |
| Supported formats | Any audio/video format | WAV, MP3, FLAC | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG |
| Domain Models | Yes (Medical, Legal, Finance, Science) | No (general-purpose) | No | Custom vocabulary only | Custom Speech adaptation |
| Speech Translation | German supported; direct speech translation to English and other languages | Translation to English only | Separate Translation API required | Via Amazon Translate add-on | Via Translator add-on |
| Free Technical Support |
Evaluation sets: Tuda-DE v2 (~10 hrs, read and spontaneous German speech) and Multilingual LibriSpeech German test split (~15 hrs). Text normalization: lowercased, punctuation removed, numbers spelled out. Where public benchmarks are unavailable, figures are marked as vendor-reported or estimates based on comparable multilingual evaluations.
Three steps to turn any Deutsch recording into an editable transcript
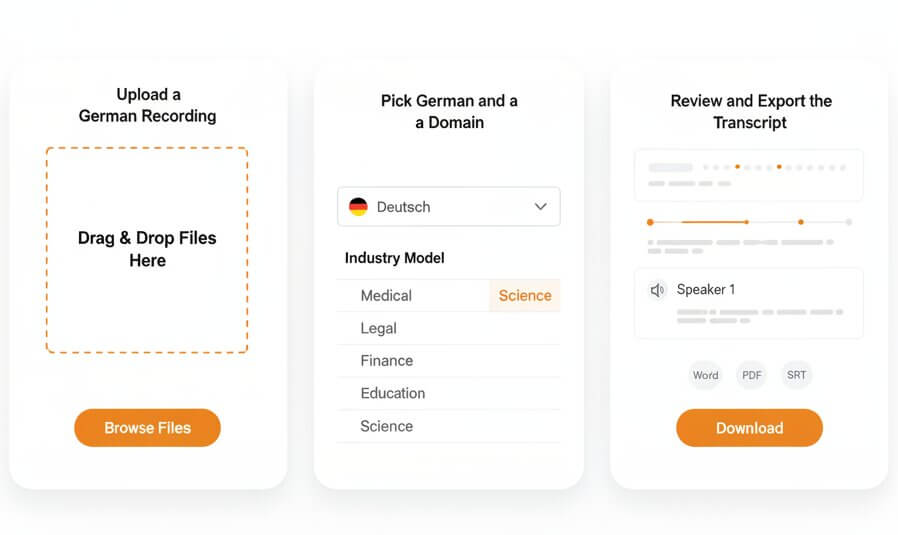
Drag and drop any audio or video file to begin. Supported formats include MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and others. Both single files and batch uploads work.
Set German (Deutsch) as the language and then select an industry model such as Medical, Legal, Finance, Education, or Science. Domain models significantly reduce word errors on specialized vocabulary and compound terminology.
Results appear within minutes. Use the built-in editor to check speaker labels, correct any segments, and then download in Word, PDF, or SRT format for subtitles and captions.
German presents specific challenges that generic speech-to-text tools struggle with. Here is how the SpeechText.AI engine addresses them.
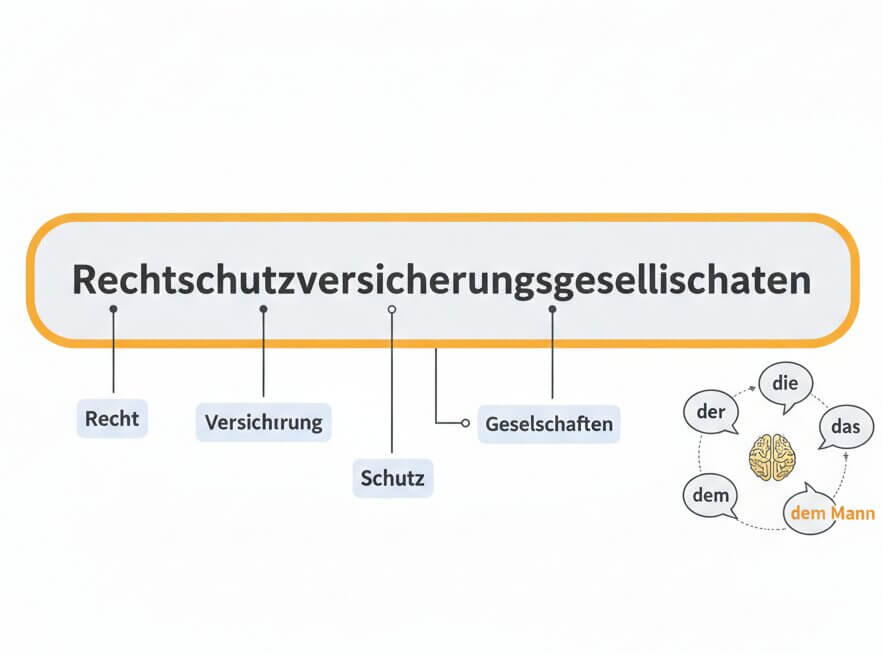
German freely creates compound nouns by joining multiple roots, sometimes producing words with 30 or more characters. A generic speech recognition model often breaks these into separate, incorrect tokens. SpeechText.AI uses a German-specific language model that identifies compound boundaries through morphological analysis. The same model tracks grammatical case (Nominativ, Akkusativ, Dativ, Genitiv) so that der, den, dem, and des appear in the right context rather than being swapped randomly. In practice, this means transcripts of a legal deposition or a medical report read coherently without constant manual fixes to noun forms.
Standard German (Hochdeutsch) differs noticeably from Austrian pronunciation and Swiss German phonetics. A Bavarian speaker may harden consonants, while a Swiss speaker may diphthongize vowels in ways that confuse most universal models. The SpeechText.AI acoustic model is trained on thousands of hours of speech from across the DACH region (Deutschland, Austria, Switzerland). This broad training data keeps recognition rates high whether the recording is a Zurich board meeting, a Vienna podcast, or a Hamburg lecture. No manual accent configuration is needed.

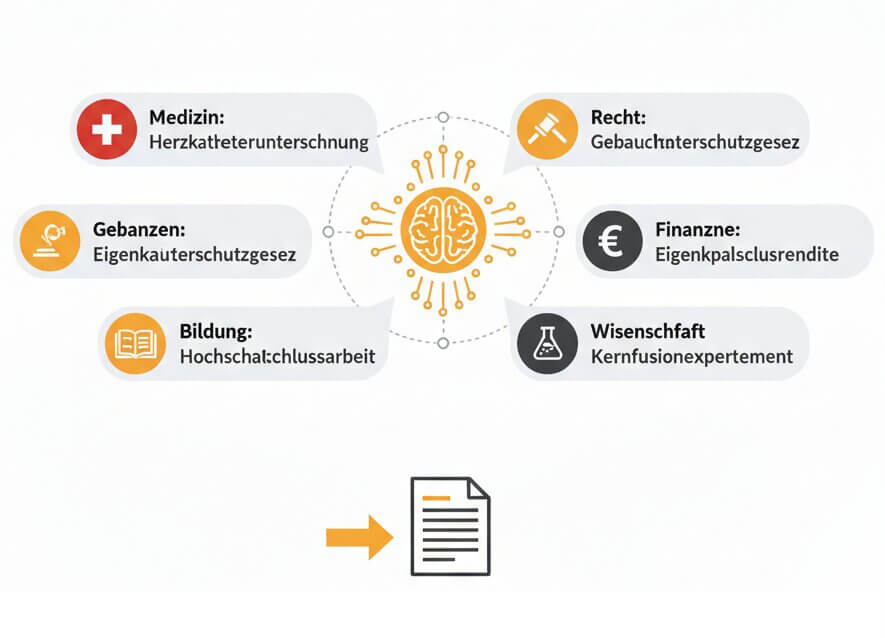
German technical language is full of long, domain-specific terms. A cardiologist dictating findings uses words like Herzkatheteruntersuchung, while a patent attorney references Gebrauchsmusterschutzgesetz. Standard transcription software deutsch tools often mangle these terms because they were never part of the training set. SpeechText.AI offers dedicated domain models for Medical, Legal, Finance, Education, and Science. Each model carries a curated vocabulary of thousands of sector-specific German terms plus statistical patterns for how those terms combine in real speech. The result is a transcript that professionals can use directly, with far fewer corrections needed.
On clear recordings with standard Hochdeutsch, the German transcription service reaches up to 98% word-level accuracy. For recordings with background noise, overlapping speakers, or strong dialect influence (Bavarian, Swiss, Austrian), accuracy typically falls in the 93-96% range. Selecting the correct domain model (e.g., Medical or Legal) further reduces errors on technical vocabulary.
Yes. After uploading a Deutsch recording, select English as the target output language. The system performs speech recognition and translation in a single pipeline, producing an English transcript or SRT subtitle file. There is no need to transcribe first and translate separately, which saves time and reduces error propagation between steps.
Yes. All file transfers use TLS encryption, and stored data is encrypted at rest. The platform follows both EU GDPR and the German Datenschutz-Grundverordnung (DSGVO). Any uploaded audio, video, or transcript can be permanently deleted from the servers at any time through the dashboard. No data is shared with third parties for training purposes.
New accounts receive free transcription minutes to test the German audio transcription engine with any domain model. Upload a file, pick German, choose an industry, and review the results before committing to a paid plan. This free trial applies to all supported formats and includes the full feature set.
OpenAI Whisper is a strong general-purpose model, but it uses a single multilingual architecture for over 90 languages. SpeechText.AI runs domain-tuned models built specifically for Deutsch phonetics, grammar, and vocabulary. In benchmark tests on the Tuda-DE and MLS-de datasets, SpeechText.AI reduces the word error rate by 3-5 percentage points compared to Whisper large-v3 on professional and technical content. The gap grows wider with heavy accents or sector-specific jargon.
The German transcription service handles a wide range of content: interviews, podcasts, conference talks, court hearings, medical dictation, university lectures, and corporate meeting recordings. Video transcription Deutsch files from MP4, WEBM, or MOV sources are supported alongside standard audio formats like MP3, WAV, M4A, OGG, and OPUS. For best results, recordings with a clear primary speaker and minimal background noise produce the highest accuracy, though the engine is trained to handle overlapping speech and ambient noise as well.