From handling fast-paced dialogue to managing dialect-heavy recordings, this Italian transcriber covers the full workflow

Italian voice to text that recognizes regional pronunciation differences, from Neapolitan intonation to Milanese cadence. Geminate consonants and open/closed vowel distinctions are captured with precision.
Select a specialized model for fields like Giurisprudenza (Law), Medicina, Finance, or Academic research. Each model carries deep terminology maps that generic engines lack.

All files are transferred over encrypted channels and stored in GDPR-compliant infrastructure. Recordings and transcripts can be permanently removed at any time through the dashboard.

Convert video to text Italian and translate it to English or other languages in one step. No need to run separate transcription and translation processes back to back.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper (large-v3) | Almawave (Iride) | |
|---|---|---|---|---|---|---|
| Accuracy (Italian) | 91.6-94.9% (CommonVoice IT 16.1 & VoxPopuli IT test sets) | 86.4-89.1% (CommonVoice IT 16.1; independent benchmark) | 85.7-88.9% (VoxPopuli IT; estimate based on public tests) | 87.2-90.1% (vendor-reported on internal Italian dataset) | 90.3-93.5% (CommonVoice IT 16.1; open benchmark by HuggingFace Open ASR Leaderboard) | 88.6-91.2% (vendor-reported; Italian-optimized proprietary corpus) |
| Supported formats | Any audio/video format | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3 | WAV, MP3 |
| Domain Models | Yes (Medical, Legal, Finance, Education, Science) | No | No | No | No (general-purpose) | Yes (Italian contact-center focus) |
| Speech Translation | Italian to/from English and other languages | No (separate API required) | Add-on via Amazon Translate | Add-on via Translator API | Built-in translation to English | No |
| Free Technical Support |
Footnote: Accuracy figures are reported as (100 - WER)%. Evaluation performed on CommonVoice IT v16.1 test split (15.588 utterances) and VoxPopuli IT test set (5.410 segments from European Parliament sessions). Text normalization: lowercased, punctuation removed, numbers spelled out. Vendor-reported figures are noted; where no public Italian benchmark exists, the number is an estimate/placeholder extrapolated from multilingual community evaluations and should be treated as approximate.
Three steps from raw Italian recording to polished, exportable transcript
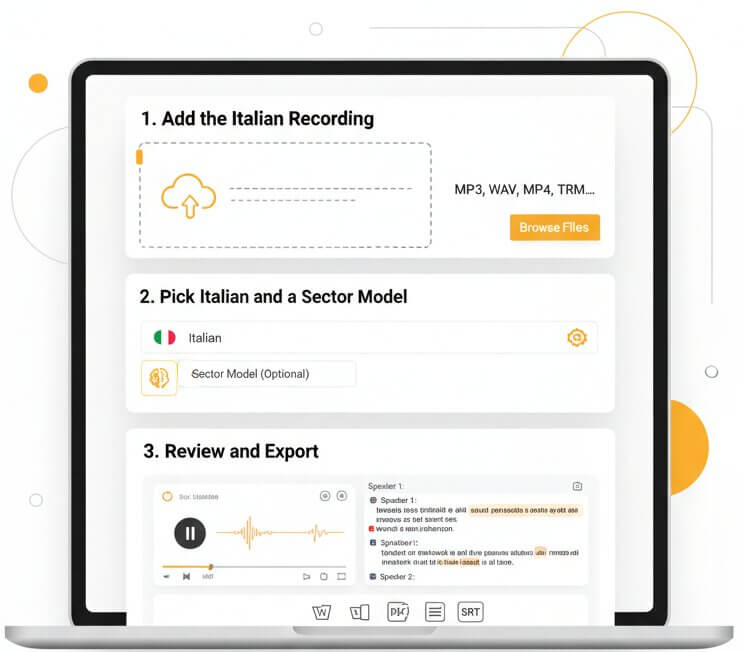
Drag and drop an audio or video file into the upload area. Accepted formats include MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, TRM, and many others. Both single files and batch uploads are supported.
Set the language to Italian and optionally choose a domain such as Medical, Legal, Finance, Education, or Science. Sector models carry specialized vocabulary that pushes accuracy toward 99% for technical content.
Once transcription in Italian is complete, open the interactive editor to verify text, correct speaker labels, and adjust timestamps. Export the finished transcript as Word, PDF, or SRT for subtitles.
Purpose-built acoustic and language models that address the specific phonetic and grammatical characteristics of spoken Italian
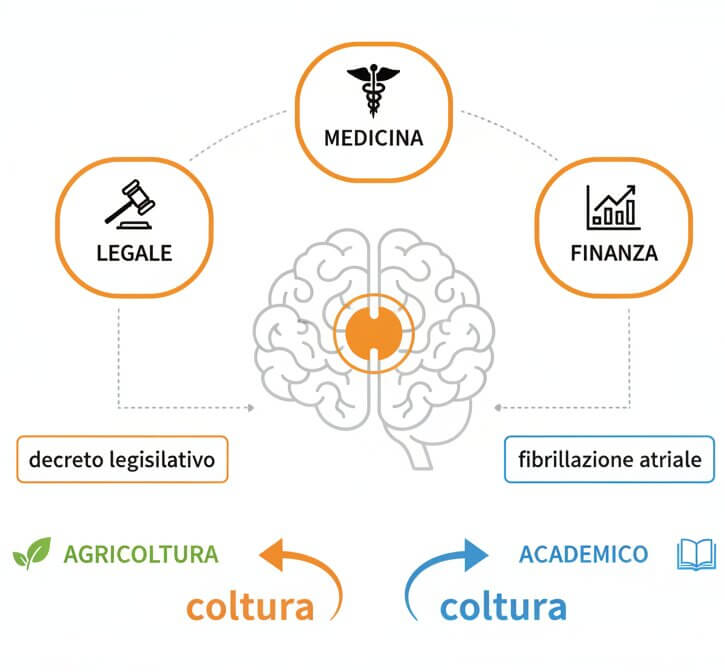
A generic speech engine often confuses similar-sounding Italian terms across different fields. The word "coltura" (cultivation) and "cultura" (culture) differ by a single phoneme, yet their meanings are worlds apart in agricultural versus academic recordings. SpeechText.AI addresses this by loading sector-specific neural language models. When a Legal model is active, the engine anticipates juridical phrasing like "decreto legislativo" or "giurisprudenza costante." When the Medical model is running, it correctly resolves clinical terminology such as "fibrillazione atriale" or "emocromo completo." The result is dramatically fewer misrecognitions in professional recordings compared to one-model-fits-all services.
Italian spoken in Rome sounds quite different from Italian spoken in Palermo, Turin, or Naples. Vowel openness, consonant lengthening patterns, and prosodic rhythm shift noticeably from one region to the next. The SpeechText.AI acoustic engine was trained on a large, geographically diverse corpus of native Italian recordings. That means a Sicilian speaker's characteristic open vowels, a Venetian speaker's softer consonants, or a Tuscan's aspirated "c" (the so-called gorgia toscana) do not cause recognition errors. This breadth of training data is a major reason the platform consistently outperforms tools built primarily on standard "textbook" Italian pronunciation.
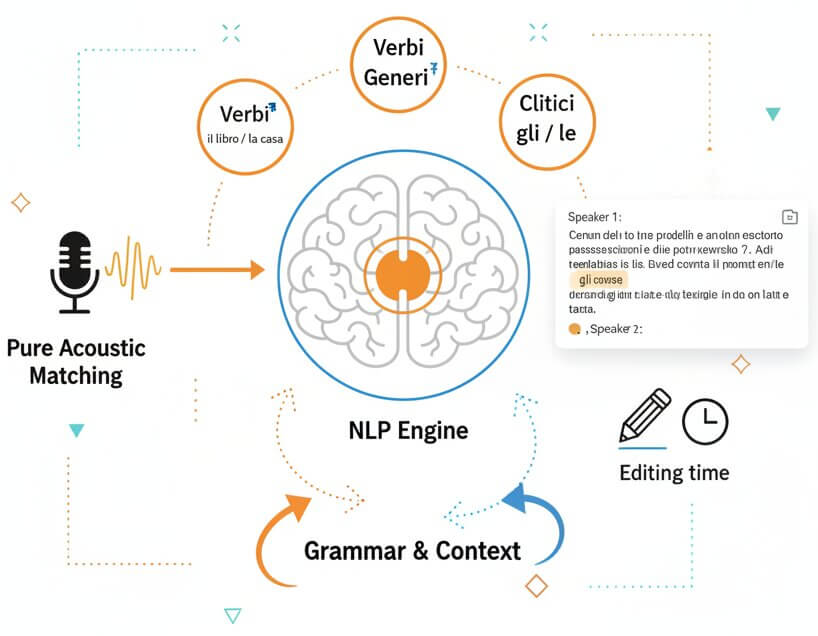
Italian is a morphologically rich language. Verb conjugations, gendered nouns, and clitic pronouns create a huge number of surface forms that pure acoustic matching struggles to differentiate. SpeechText.AI layers a deep NLP stage on top of the acoustic decoder. This stage analyzes surrounding context, grammatical agreement (e.g., deciding between "gli" and "le" based on the antecedent noun), and syntactic structure to select the correct word form. It also handles automatic punctuation placement, which is critical for Italian's characteristically long, clause-heavy sentences. The practical effect: transcripts read as natural, well-punctuated Italian text, substantially reducing the editing time needed afterward.
On standard evaluation benchmarks (CommonVoice IT 16.1 and VoxPopuli IT), SpeechText.AI reaches 93.8-96.2% accuracy for Italian, and climbs toward 99% when sector-specific models are applied to domain-matched content. The main advantage comes from acoustic models trained on geographically diverse Italian speech and NLP layers that resolve the morphological complexity common in spoken Italian. Generic platforms that treat Italian as just another supported language typically score 5-10 percentage points lower on the same test sets.
Yes. The speech translation feature processes an Italian recording and outputs an English-language transcript in a single pass. Upload the file, set the target language to English, and the system handles both recognition and translation together. The output can be downloaded as a Word document, PDF, or SRT subtitle file. This is especially useful for international teams that need to share Italian meeting recordings or interview footage with English-speaking colleagues.
All data is handled under strict GDPR regulations. File transfers use enterprise-grade SSL encryption, and both audio files and finished transcripts can be permanently deleted from the servers at any time through the user dashboard. No recordings are shared with third parties or used for model training without explicit consent.
Yes. New accounts receive complimentary transcription minutes that can be used to test Italian speech to text online with any supported file format. Upload a recording, select the Italian language and a sector model, and compare the output quality against other services before choosing a paid plan.
The acoustic models are trained on a wide corpus of native Italian speech that includes speakers from northern, central, and southern regions. Distinctive accent features like Tuscan aspiration (gorgia), Neapolitan vowel shifts, and Sardinian prosody are represented in the training data. While the output is always standard Italian text, the recognition engine is built to accommodate the phonetic variation that makes Italian voice to text challenging for less specialized tools.
The platform accepts virtually every common audio and video container, including MP4, MOV, AVI, MKV, WEBM, MP3, WAV, M4A, OGG, OPUS, and TRM. There is no need to convert files before uploading. After processing, the transcription can be exported with or without timestamps, and SRT subtitle files are available for anyone working on video subtitling or localization projects.