
Speech recognition service for Ogg Vorbis containers. Transcribe .oga files with human-level accuracy.

Deep learning models trained on diverse speech patterns deliver reliable results across dialects and recording conditions
Files processed on EU-hosted servers with encryption at rest and in transit, meeting GDPR standards
Select recognition engines optimized for technical, medical, financial, or conversational audio contexts
Download finished transcripts as editable documents (DOCX, TXT), structured data (XLSX), or timed subtitles (SRT, VTT)
Three steps to transform OGA audio into searchable, timestamped text
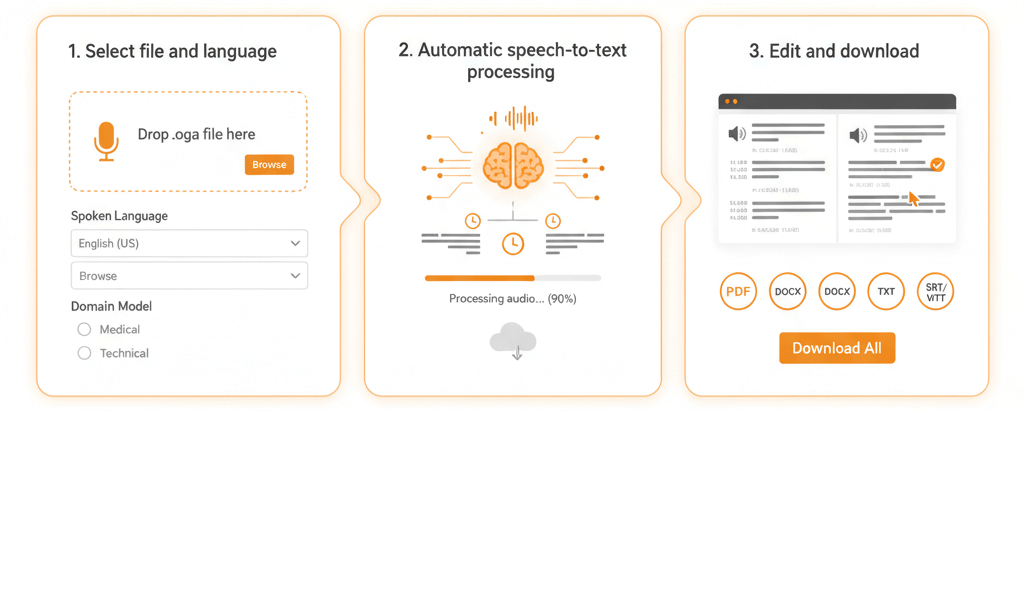
Drop the .oga file into the upload zone. Pick the spoken language and, if applicable, a domain-specific recognition model such as legal terminology, medical vocabulary, or technical jargon to improve output quality.
AI algorithms decode the OGA audio stream, identify spoken words, assign timestamps, and separate speakers when multiple voices are present. Processing happens server-side without installing software or plugins.
Review the completed transcript in the built-in editor, correct any errors, then export to the preferred format: PDF for sharing, DOCX for further editing, TXT for plain data, or SRT and VTT for video captioning.
OGA is an open-source Ogg Vorbis container widely adopted in gaming, web applications, and cross-platform projects
OGA is the file extension for Ogg Vorbis audio, an open, patent-free codec developed by the Xiph.Org Foundation. Unlike proprietary formats, Ogg Vorbis compresses audio efficiently while remaining free to use and implement, which explains its popularity in open-source software, games, and web platforms.
OGA files appear frequently in video games (dialogue, effects, ambient sound), Linux desktop environments, web-based audio players, and streaming services that prioritize open standards. Developers favor OGA when licensing costs or platform independence matter. It delivers solid audio fidelity in a smaller package than uncompressed WAV.
Converting OGA speech to text unlocks spoken content for indexing, analysis, and reuse. Game studios extract dialogue for localization and quality assurance. Journalists mine interview recordings for quotes without manual playback. Educators build searchable lecture archives. Accessibility requirements are met by pairing OGA media with accurate captions or transcripts.
From indie game studios to enterprise training libraries, OGA audio transcription serves diverse industries and workflows
Upload the .oga file, select the language spoken in the recording, initiate transcription, then download the finished text in PDF, DOCX, TXT, or subtitle format once processing completes.
A free trial is available to test the full transcription engine without payment or commitment. This trial allows conversion of OGA files to text and exploration of all export formats and editing tools.
Yes. After transcription finishes, the text can be exported directly as a formatted PDF document. Other available formats include Microsoft Word (DOCX), spreadsheet (XLSX), plain text (TXT), and subtitle files (SRT, VTT).
Recognition accuracy depends on audio clarity, speaker accent, background noise, and terminology complexity. Clean OGA recordings with clear speech typically achieve over 90% accuracy. Domain-specific models further improve results for specialized vocabulary.
Timestamps are included by default. Each segment of transcribed text is tagged with its start time, allowing precise navigation back to the corresponding moment in the original OGA file. Timestamp formats adapt to the chosen export type.
Advanced speech recognition requires server-side AI models for accuracy. Files are encrypted during transfer and automatically deleted after processing, ensuring confidentiality even with cloud-based transcription.