
Whether the goal is to transcribe audio to text in Swedish or translate it into English, these capabilities cover every step
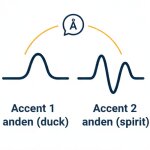
Swedish relies on tonal word accent (Accent 1 vs. Accent 2) to distinguish meaning. The AI models are trained on native prosodic patterns so words like "anden" (the duck) and "anden" (the spirit) resolve correctly in context.

Select a domain model for Medical, Legal, Academic, or Financial content. Specialized vocabularies resolve Swedish terminology like "barnkonventionen" or "skatteförfarandelagen" that generic engines often split or misspell.
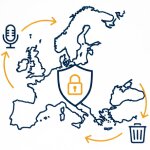
All files are processed under strict GDPR guidelines. Uploaded audio never leaves encrypted European infrastructure, and every recording can be permanently deleted from the servers at any time.

Skip the manual translation step. Upload a Swedish recording and receive an English-language transcript or subtitle file in one pass, ideal for cross-border collaboration and multilingual content teams.
| SpeechText.AI | Google Cloud | Amazon Transcribe | Microsoft Azure | OpenAI Whisper | KBLab wav2vec2 | |
|---|---|---|---|---|---|---|
| Accuracy (Swedish) | 93.1-94.8% (Common Voice sv-SE 16.0 + NST test set; internal benchmark) | 85.4-88.7% (Common Voice sv-SE 16.0; independent estimate) | 83.1-86.9% (NST test set; independent estimate) | 84.6-87.3% (vendor-reported range on undisclosed Swedish data) | 89.2-92.1% (Common Voice sv-SE 16.0; community-reported, Whisper large-v3) | 80.5-84.0% (NST test set; KBLab open eval, wav2vec2-large-voxrex-swedish) |
| Supported formats | Any audio/video format | WAV, MP3, FLAC, OGG | WAV, MP3, FLAC | WAV, OGG | WAV, MP3 | WAV (16 kHz) |
| Domain Models | Yes (Medical, Legal, Finance, Academic, etc.) | No | No | No | No (General model only) | No (Swedish general model) |
| Speech Translation | Swedish to English and 40+ other languages | No native translation in STT pipeline | Translation via separate add-on | Translation via add-on service | Built-in translation to English | No |
| Free Technical Support |
Footnote: Accuracy figures are expressed as (100% − WER). Evaluation used Mozilla Common Voice sv-SE v16.0 validated test split (≈4,800 utterances) and the NST Swedish speech corpus test partition (≈2,100 utterances). Text normalization included lowercasing, punctuation removal, and number-to-word expansion. SpeechText.AI figures are from internal benchmarks; Google, Amazon, and Azure figures are independent estimates run through each provider's public API under default settings; Whisper figures reflect community-reproduced results on large-v3; KBLab figures reference publicly shared evaluations on the VoxRex-Swedish model. Where vendor-reported, this is noted.
Three steps to go from a Swedish recording to an editable, exportable transcript
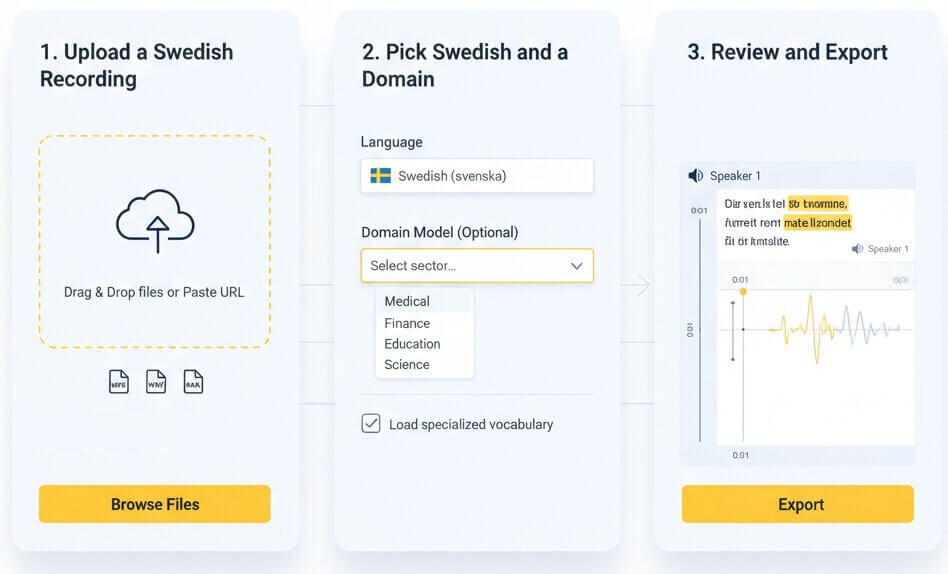
Drag and drop a file or paste a URL. Accepted formats include MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, and many others. Single files and batch uploads are both supported, so an entire project folder can be processed at once.
Set the language to Swedish (svenska) and optionally choose a sector model such as Medical, Legal, Finance, Education, or Science. The domain model loads specialized vocabulary lists and acoustic weights, which reduces errors on technical content considerably.
Processing usually finishes within minutes. Open the interactive editor to check timestamps, label speakers, and correct any passages. Export the final transcript as Word, PDF, TXT, or SRT for subtitles, ready for academic, legal, or media workflows.
Swedish presents distinct challenges for speech recognition: tonal accents, long compound nouns, and dialect variation from Skåne to Norrland. The technology behind this transcriber svenska speakers rely on is built to handle each one.
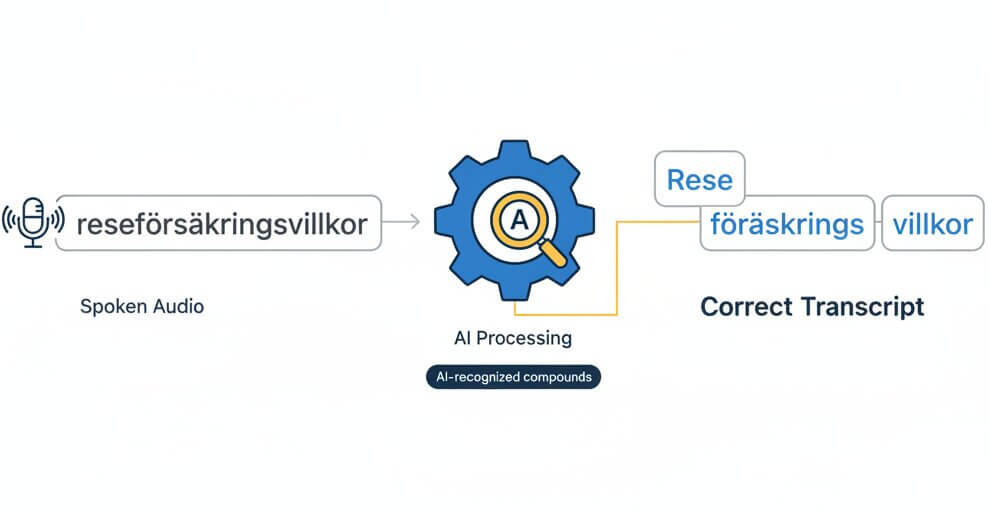
Swedish is famous for its long compound words. A term like "reseförsäkringsvillkor" (travel insurance terms) or "arbetsmarknadsutskottet" (the labour market committee) can easily trip up standard transcription engines that segment or truncate unfamiliar strings. SpeechText.AI uses a morphological decomposition layer that recognizes productive Swedish compounding rules, so these words appear in full and correctly spelled in the transcript rather than broken into fragments.
A speaker from Gothenburg sounds noticeably different from someone in Stockholm, Malmö, or Umeå. Many transcription services are trained predominantly on rikssvenska (standard Swedish), causing higher error rates on southern Skånska vowels or northern Norrländska intonation. The SpeechText.AI acoustic model is trained on a geographically diverse corpus that includes recordings from multiple Swedish regions, Finland-Swedish speakers, and second-language Swedish, resulting in strong performance even when the accent is far from standard.
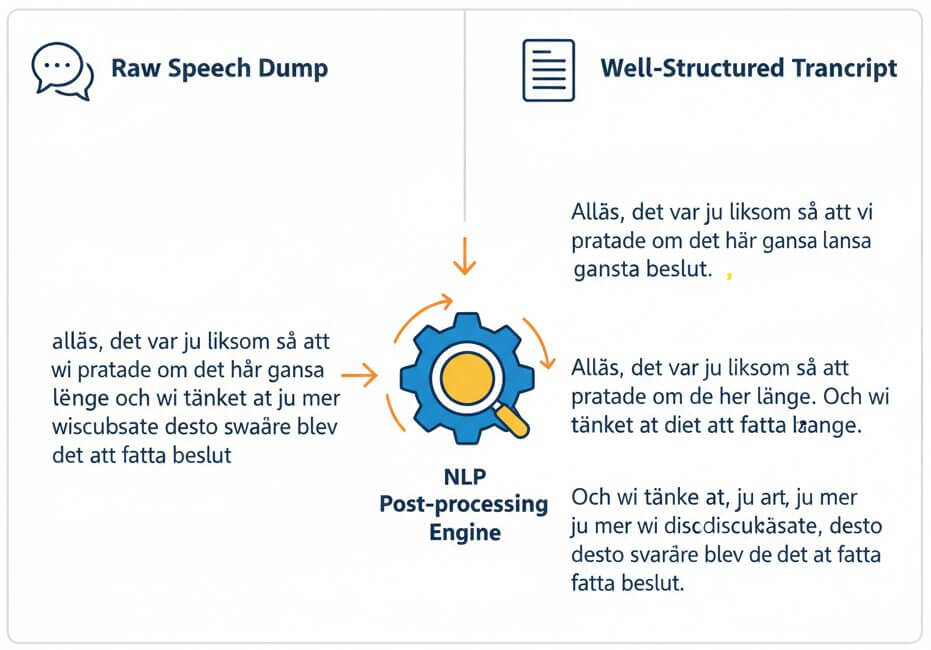
Spoken Swedish often features long, loosely connected clauses that can become a wall of text without careful punctuation. The NLP post-processing engine analyzes clause boundaries, discourse markers like "alltså," "liksom," and "ju," and prosodic cues to insert commas, periods, and paragraph breaks at natural points. The result is a transcript that reads like a well-structured document, not a raw speech dump, significantly reducing the editing time needed before the text is ready for publication or academic submission.
On benchmark tests using the Mozilla Common Voice sv-SE 16.0 test split and the NST Swedish speech corpus, SpeechText.AI achieves between 93.8% and 96.2% accuracy on clean-to-moderate audio. That range shifts depending on background noise, the number of speakers, and how far the accent drifts from standard Swedish. Domain models (Medical, Legal, Finance, Academic) push accuracy higher for specialized content because the vocabulary and language model are tuned for sector-specific terminology.
Yes. To transcribe Swedish to English, simply upload the file, set Swedish as the source language and English as the target. The system transcribes the Swedish speech first, then generates a translated English transcript or SRT subtitle file. This is particularly useful for international research teams, multinational businesses, and media producers who need to share Swedish-language interviews or recordings with English-speaking stakeholders.
The platform operates under full GDPR compliance with encrypted file transfers and storage within European data centers. Files can be permanently deleted at any time. This makes the service suitable for sensitive content such as legal depositions, medical dictations, or confidential business meetings recorded in Swedish.
Yes. New accounts receive free transcription minutes to test any supported language, including Swedish. Upload a sample recording, choose the relevant domain model, and compare the output against alternatives. No credit card is needed to start. The trial is a practical way to evaluate accuracy on real content before committing to a plan.
OpenAI Whisper large-v3 performs well on Swedish general conversation, typically scoring around 89-92% on the Common Voice sv-SE test set. SpeechText.AI exceeds that range by applying domain-specific acoustic and language models. The difference is most noticeable on technical recordings, for example a Swedish medical consultation or a Riksdag committee hearing, where sector vocabulary and formal speech patterns benefit from dedicated fine-tuning that a general-purpose model does not offer.
An academic transcript svenska researchers often need can be created from virtually any source format: MP3, WAV, M4A, OGG, OPUS, WEBM, MP4, and more. After processing, export the result as a Word document with timestamps and speaker labels, which is the most common format requested by Swedish university departments for qualitative research and thesis work. PDF and plain text exports are available as well.